|
|

|

|
| e-Pub |
Section: New Results
Human Action Recognition in Videos
Participants : Piotr Bilinski, François Brémond.
Keywords: Action Recognition, Video Covariance Matrix Logarithm, VCML, Descriptor
Video Covariance Matrix Logarithm for Human Action Recognition in Videos
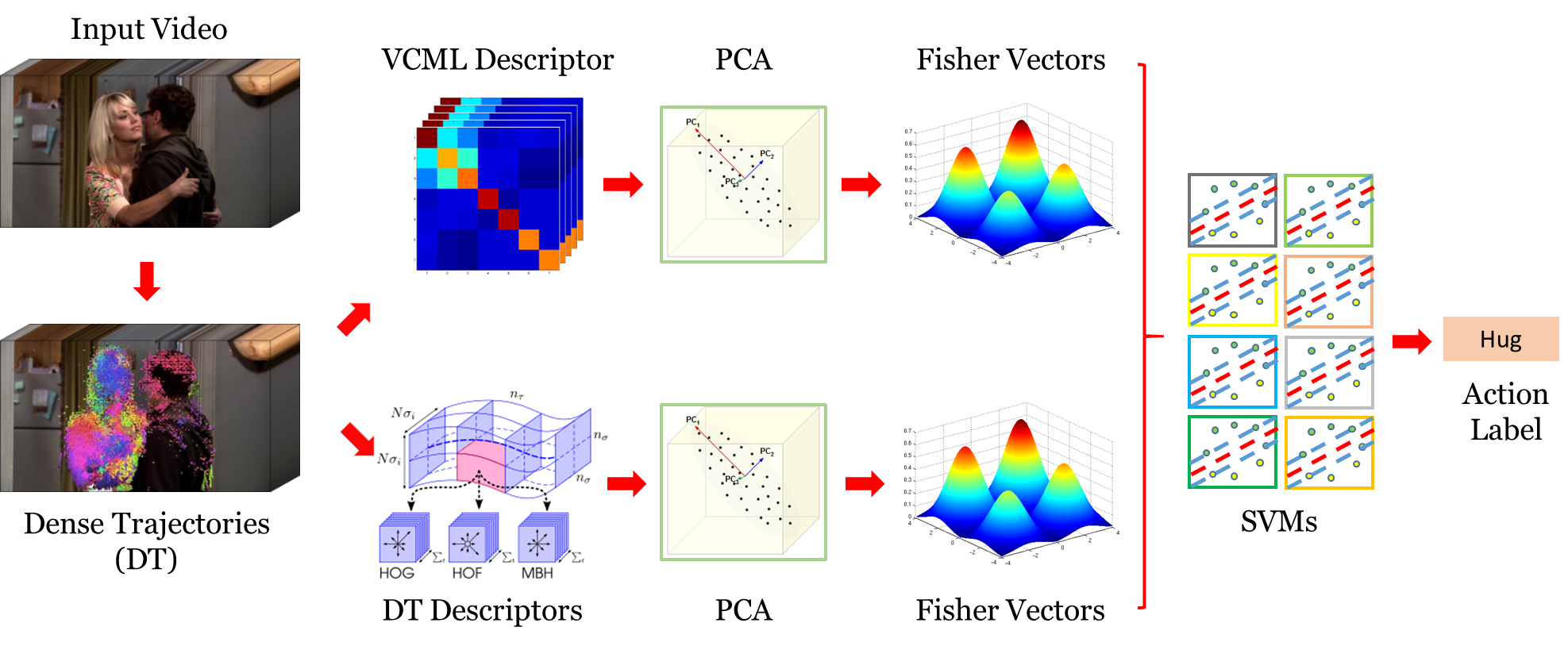
In this work, we propose a new local spatio-temporal descriptor for videos and we propose a new approach for action recognition in videos based on the introduced descriptor. Overview of the proposed action recognition approach based on the introduced descriptor is presented in Figure 17 . The new descriptor is called the Video Covariance Matrix Logarithm (VCML). The VCML descriptor is based on a covariance matrix representation, and it models relationships between different low-level features, such as intensity and gradient. We apply the VCML descriptor to encode appearance information of local spatio-temporal video volumes, which are extracted by the (Improved) Dense Trajectories. Then, we present an extensive evaluation of the proposed VCML descriptor with the (Improved) Fisher Vector encoding and the Support Vector Machines on four challenging action recognition datasets (i.e. URADL, MSR Daily Activity 3D, UCF50, and HMDB51 datasets). We show that the VCML descriptor achieves better results than the state-of-the-art appearance descriptors. In comparison with the most popular visual appearance descriptor, i.e.the HOG descriptor, the VCML achieves superior results. Moreover, we present that the VCML descriptor carries complementary information to the HOG descriptor and their fusion gives a significant improvement in action recognition accuracy (e.g. the VCML improves the HOG by 15% on the HMDB51 dataset). Finally, we show that the VCML descriptor improves action recognition accuracy in comparison to the state-of-the-art (Improved) Dense Trajectories, and that the proposed approach achieves superior performance to the state-of-the-art methods. The proposed VCML based technique achieves accuracy on the URADL dataset, on the MSR Daily Activity 3D dataset, on the UCF50 dataset, and on the HMDB51 dataset. More results and comparisons with the state-of-the-art are presented in Table 9 and Table 10 . To the best of our knowledge, this is the first time covariance based features are used to represent the trajectories. Moreover, this is the first time they encode the structural information and they are applied with the (Improved) Fisher Vector encoding for human action recognition in videos. This work has been published in [40] .
| URADL | MSR Daily Activity 3D | ||
| Benabbas et Al., 2010 | 81.0 | Koperski et Al., 2014 | 72.0 |
| Raptis and Soatto, 2010 | 82.7 | JPF – Wang et Al., 2012 | 78.0 |
| Messing et Al., 2009 | 89.0 | Oreifej and Liu, 2013 | 80.0 |
| Bilinski and Bremond, 2012 | 93.3 | AE – Wang et Al., 2012 | 85.7 |
| Dense Trajectories | 94.0 | Dense Trajectories | 76.2 |
| Our Approach (DT) | 94.0 | Our Approach (DT) | 78.1 |
| Our Approach (IDT) | 94.7 | Our Approach (IDT) | 85.9 |
| UCF50 | HMDB51 | ||
| Kantorov and Laptev, 2014 | 82.2 | Kantorov and Laptev, 2014 | 46.7 |
| Shi et Al., 2013 | 83.3 | Jain et Al., 2013 | 52.1 |
| Oneata et Al., 2013 | 90.0 | Oneata et Al., 2013 | 54.8 |
| Wang and Schmid, 2013 | 91.2 | Wang and Schmid, 2013 | 57.2 |
| Dense Trajectories | 84.2 | Dense Trajectories | 47.0 |
| Our Approach (DT) | 88.1 | Our Approach (DT) | 52.9 |
| Our Approach (IDT) | 92.1 | Our Approach (IDT) | 58.6 |